I ran into an interesting problem with a network this last few weeks.
At first, it seemed like intermittent responsiveness issues with the network. Most of the time it seemed to be working properly, but from time to time, management access would completely cut out (serial console seemed to be uneffected).
Topology
First, the topology.
{% blockdiag nwdiag { class obj_fw [shape = cisco.pix_firewall]; class obj_l3sw [shape = cisco.layer_3_switch];
inet [label="Internet", shape = cloud];
srx340 [label="srx", class = obj_fw];
ex2300-1 [label="sw1", class = obj_l3sw];
ex2300-2 [label="sw2", class = obj_l3sw];
ex2300-3 [label="sw3", class = obj_l3sw];
ex2300-4 [label="sw4", class = obj_l3sw];
ex2300-5 [label="sw5", class = obj_l3sw];
ex2300-6 [label="sw6", class = obj_l3sw];
inet -- srx340;
network dmz {
address = "192.168.0.0/24";
srx340 [address = "192.168.0.1"];
ex2300-1;
ex2300-2;
ex2300-3;
ex2300-4;
ex2300-5;
ex2300-6;
group L2 {
ex2300-1;
ex2300-2;
ex2300-3;
ex2300-4;
ex2300-5;
ex2300-6;
}
}
network lan {
group L2 {
ex2300-1;
ex2300-2;
ex2300-3;
ex2300-4;
ex2300-5;
ex2300-6;
}
address = "172.16.32.0/24";
srx340 [address = "172.16.32.1"];
ex2300-1 [address = "172.16.32.10"];
ex2300-2 [address = "172.16.32.11"];
ex2300-3 [address = "172.16.32.12"];
ex2300-4 [address = "172.16.32.13"];
ex2300-5 [address = "172.16.32.14"];
ex2300-6 [address = "172.16.32.15"];
}
}
%}
Very simple. Daisy chain from the SRX all the way through to the last switch. SRX -> switch1 -> switch2 -> … -> switch6
General Infrastructure
We have a DNS/DHCP server on the LAN. Standard unbound and isc-dhcpd configurations. The DNS/DHCP server is plugged into switch1.
The SRX is doing both L2 and L3 (irb.X interface for each VLAN). It’s the gateway for the LAN, any other local networks, and performs NAT for connections that leave the local networks (internet).
Switches
The switches have a very simple and straight forward configuration. Since they are all a flat L2 network, they have an irb interface for management, a handful of VLANs, and RSTP (all ports). There are a collection of ports that are PoE for various things.
What we observed
If you’re not familiar with the packets involved in a dhcp conversation, you can check out cloudshark dhcp packet .
Initially we were trying to determine why the dhcp leases file was 100MB. A couple greps and we had something odd.
1[louisk@mpro louisk 11 ]$ cat /var/dhcpd/var/db/dhcpd.leases | grep -cE "^lease .+ {"
2195647
3[louisk@mpro louisk 12 ]$
That seems like a lot of leases. Adjusting the expression for individual hosts, we found that some hosts had >40k lease entries, and one host had >100k lease entries. You’re wondering how long the leases file has been getting filled up. It was only a few weeks old. More interestingly, it appeared that hosts were making dozens of requests at the same time. Just to make sure, we truncated the leases file and watched it. It started filling up. In <4hrs, there were hosts that hand >10k lease entries. Yet it still seemed like the DHCP server was doing what it was supposed to.
Odd.
Time to get out tcpdump and see if what we think is going on, is actually going on. Running tcpdump on the dhcp server does in fact show a multitude of requests coming from the client, all at the same time. It does appear that the server is acknowledging each incoming request, hence the plethora of entries in the lease file.
So far, so good. DHCP isn’t behaving the way we expect, but it still seems to be doing what its supposed to.
Tcpdump on the client shows that the client is only sending out 1 request. That doesn’t quite match up with what we saw on the server. More strangely, we the number of dhcp replies seemed to be greater than the number of requests.
Confusing.
Is the server actually sending multiple ack’s for each request? Time to
tcpdump both client and server, at the same time. Filter is port 67 or port 68 and ether host <mac address>. Comparing these, gets more interesting, the client
thinks it sent a single request. The server sees multiple requests. It
responds with 1 ack for each request it receives. The client sees more
acks than the server sent. How can the client and server have different
opinions about what packets are doing on the network? It could make sense if
the number was smaller, something like packet loss could account for it, but
not an increase in the number of packets. Time to brainstorm. What kinds of
wild ideas can we come up for why packets would be multiplying?
Digging into the tcpdumps a little more, and writing it on the white board helps.
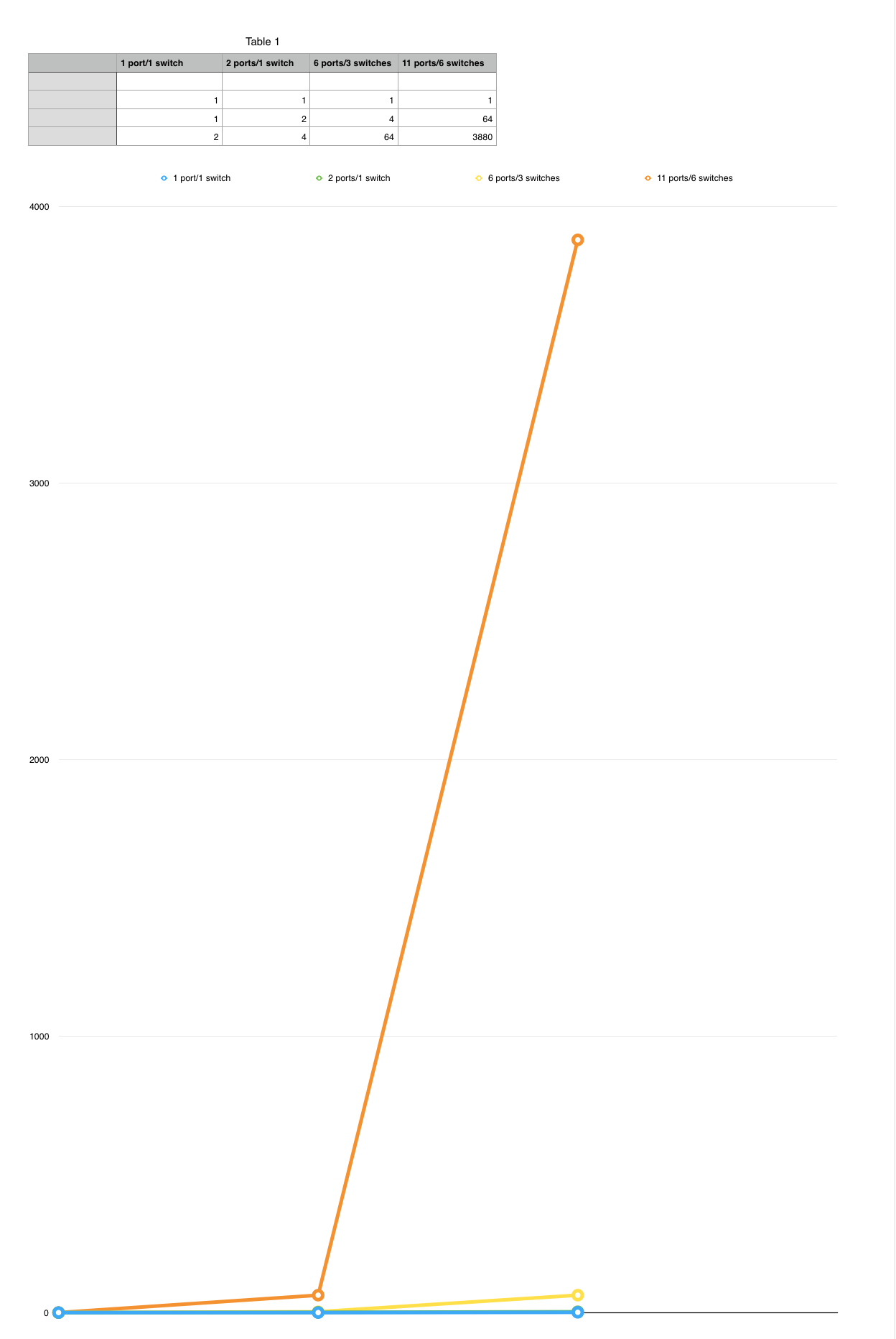
Scenario 1 - client plugged into switch3
- dhcp client sends 1 dhcp request
- dhcp server sees 4 requests
- dhcp server sends 4 acknowledgements
- dhcp client sees 64 acknowledgements
Scenario 2 - client plugged into switch6
- dhcp client sends 1 dhcp request
- dhcp server sees 64 requests
- dhcp server sends 64 acknowledgements
- dhcp client sees 3,880 acknowledgements
Scenario 3 - client plugged into switch1
- dhcp client sends 1 dhcp request
- dhcp server sees 2 requests
- dhcp server sends 2 acknowledgements
- dhcp client sees 4 acknowledgements
Scenario 4 - client plugged into switch1, dhcp server configured in switch1
- dhcp client sends 1 dhcp request
- dhcp server sees 1 request
- dhcp server sends 1 acknowledgement
- dhcp client sees 2 acknowledgements
At first glance, there doesn’t seem to be much in common here, other than in every scenario, the client thinks it sent 1 request, and got back an abnormal number of replies, and the server seems to acknowledge each reqeust (as its supposed to).
- Scenario 1, the packet has to cross 3 switches. 4 trunk ports. Might be interesting. 6 total ports. Don’t see a pattern yet.
- Scenario 2, the packet has to cross 6 switches. 9 trunk ports. 11 total ports. Don’t see a pattern here either.
- Scenario 3, the packet stays in the same switch. 0 trunk ports. 2 access ports. Not sure about a pattern.
- Scenario 4, the packet stays in the same switch. 0 trunk ports. 1 access port. This may rule out the DHCP server as the problem. We still see more packets than we should, and we’re now using a totally different dhcp server.
It seems like we’re seeing packet multiplication, somehow. Do we get anything from the graph (at the bottom)? Obviously it gets big pretty fast, but we knew that already. It kind of looks exponential. The more switches (ports?) we traverse, the bigger it gets. Doubling every port? Doubling every switch? Scenario 4 seems to say it can’t be doubling for the switch because it doesn’t double until the return trip. Scenario 3 can’t be doubling per switch, because there is only 1 switch, but could be doubling for the port. Scenario 1 6 ports. If we double things for each port, we have 64. That doesn’t fit. If we double for each switch, scenario 4 doesn’t quite make sense. What about the others? For scenario 1, seems like it should be 8 that arrive instead of 4. Even though the numbers don’t quite match up, definitely feels like we’re on to something.
Resolution
Well, not yet. The temporary resolution was to downgrade to 15.1X53-D55. There is a PR that has been opened for this case (1326857). JTAC has been able to replicate it in their lab, and will be following up with engineering for a real solution.

Comments